AI原生编程入门及其实践
本文重理论,轻实践。
AI原生开发相关概念
基石-机器学习
线性回归
假设我们有一组数据(例如:房屋面积和房价)。有若干样本,类似(80,400),(132,300),线性回归试图通过一个数学方程式来描述它们的关系:
定义损失函数,找一使损失函数最小的 \(w, b\)。这个 \(w, b\) 就是我们的预测模型的参数。
计算机训练
- 数学方程式:GPT-4 / GPT-4o 据传总参数量达到了 1.8T(即 1.8 万亿)
- 80% 训练集,20% 测试集
- 梯度下降
- 当 MSE 小于某个阈值就可以
- 阈值和梯度值的选择决定了训练速度和模型质量
大模型
- 用海量文本学一个"下一个词/符号出现的概率模型"
- 语料 → token 序列 → \(x=(x_1, x_2, \ldots, x_T)\)
- 样本模型在每个位置 \(t\),\(X(t-1) = (x_0, x_1, x_2, \ldots, x_{t-1})\),\(Y_t = x_t\)
- 神经网络只是用了拟人化的方式建立了一个数学表达式来描述数据间的关系,本质还是回归
- 损失函数:条件概率 + 交叉熵/最大似然
三大支柱
- 可执行的规范定义"做什么"
- 基于持久化的上下文理解"怎么做"
- 通过可编排的行动来"完成它"
可执行的规范(Specs)- 规范驱动开发(Spec-Driven Development, SDD)
在 AI 原生工作流中,一份好的需求规格说明(Specification,简称 Spec),例如 spec.md,其本身就应该是一份"意图代码"。它不再是写给产品经理或开发者的散文,而是一份结构化的、可被 AI 精确理解和执行的"高级语言"。
AI Agent 会像编译器解释代码一样,将这份"意图代码"逐步"编译"为技术方案(plan.md)、任务列表(tasks.md),最终生成可运行的业务代码。这意味着,维护软件的核心,从维护易变的代码,转向了维护更稳定的规范。当需求变更时,我们首先修改 spec.md,然后驱动 AI 重新生成实现。
持久化的上下文
旨在彻底解决我们作为"上下文搬运工"的窘境。当 AI 开始工作时,它会像加载配置文件一样,自动将这些上下文融入自己的"世界观"中。它给出的每一行代码,都将是"戴着镣铐跳舞",既符合你的个人习惯,也遵循团队的规范和公司的要求。
通过 CLAUDE.md、agents.md、rules 这类标准化的上下文文件,可以为 AI 提供关于项目的"长期记忆"。更重要的是,这种记忆是分层的、持久化的:
- 企业级记忆:整个公司的安全红线、合规要求
- 项目级记忆:
constitution.md中定义的技术选型、架构原则、编码"宪法" - 模块级记忆:特定模块的 API 设计、核心逻辑
- 个人级记忆:你个人的代码风格偏好
可编排的行动
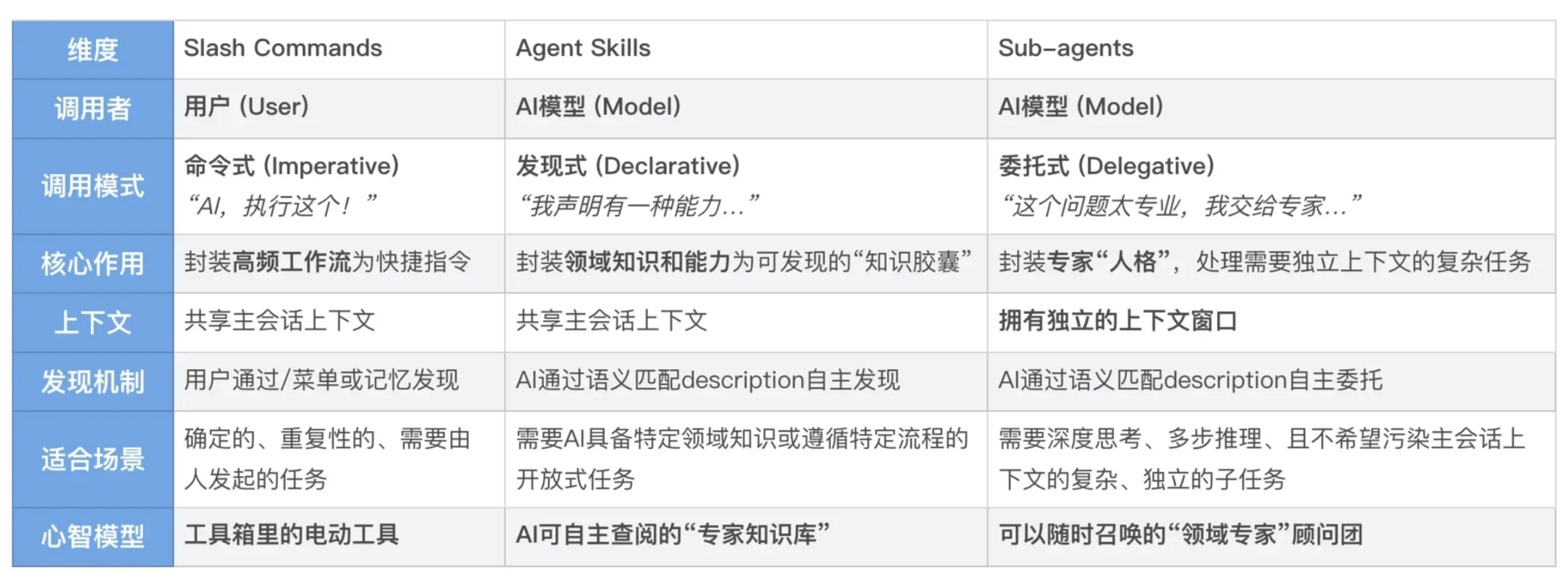
它赋予 AI 执行具体任务的能力。在 AI 原生工作流中,AI 不仅仅能调用内置的工具(如读写文件、执行 Shell 命令),更重要的是,我们可以通过自定义指令(Slash Commands)、钩子(Hooks)和 MCP 服务器,为它打造一个几乎无限扩展的"工具箱"。
Slash Command
自定义指令的核心,就是将模式化的、蕴含隐性知识的高频工作流,从一个需要你每次都详细描述的"动态 Prompt",变成一个固化下来、可一键调用的"静态模板"。
特点:
- 高频:你每天可能都要做好几次,甚至更多
- 模式化:每次执行的步骤和核心意图都高度相似
- 蕴含隐性知识:比如"符合我们团队规范"这个要求,背后包含了大量的上下文和约束
示例:review_pull_request.md
---
name: review_pull_request
argument-hint: [pr-number] [priority] [assignee]
description: Review pull request
model: opus
allowed-tools: Bash(go test:*), Write
---
Review PR #$1 with priority $2 and assign to $3.
Focus on security, performance, and code style.
Hooks
Hooks 是"事件驱动"的。它们是你预先设置在 AI 行动路径上的"传感器"和"响应器"。当 AI 生命周期中的某个事件(比如"AI 刚刚完成了一次文件写入")发生时,对应的 Hook 会自动被触发,执行你预设好的响应动作。它致力于将孤立的 AI 行动,连接成更流畅的自动化序列。
示例配置:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{
"type": "command",
"command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/markdown_formatter.py"
}
]
}
]
}
}
Hooks 的应用场景:
- 通知:自定义当 Claude Code 等待你的输入或运行权限时如何通知你
- 自动格式化:在每次文件编辑后,对
.ts文件运行 prettier,对.go文件运行 gofmt 等 - 日志记录:跟踪和统计所有执行的命令,用于合规或调试
- 反馈:当 Claude Code 生成的代码不符合你的代码库规范时,提供自动化反馈
- 自定义权限:阻止对生产文件或敏感目录的修改
MCP
AI Agent 最强大的能力——连接外部世界。不再满足于让 AI 在本地的"沙盒"里工作,而是为它装上了可以触及云端服务的"长臂"。
MCP 的强大之处,不仅在于暴露"工具(Tools)",还在于可以暴露"提示(Prompts)"。一个设计良好的 MCP 服务器,可以将其内部复杂的、经过优化的 Prompt,封装成一个简单的 Slash Command,供你在 Agent 中直接调用。
Skills - 行业标准
指令(如 Slash Command):是一个"祈使句"。它由用户发起,明确地告诉 AI"去做这件事"。例如,/review-go-code。
技能(Skill):是一段"陈述句"。它由开发者预先定义,安静地躺在那里,向 AI"自我介绍":"我是一种能做某件事的能力"。例如,"我是一个能够根据 Go 项目规范审查代码的技能"。
Skill Description
---
name: your-skill-name
description: Brief description of what this Skill does and when to use it
---
# Your Skill Name
## Instructions
Provide clear, step-by-step guidance for Claude.
## Examples
Show concrete examples of using this Skill.
Support Files
my-skill/
├── SKILL.md (required)
├── reference.md (optional documentation)
├── examples.md (optional examples)
├── scripts/
│ └── helper.py (optional utility)
└── templates/
└── template.txt (optional template)
Discoverable Capabilities

codex 加载:
- 通过
~/.codex/skills确认下你当前可以使用的技能清单 - 读取
/Users/KakaYin/WorkSpace/DiveAI/CodexSkill/TestCase/sample_text_english.pdf的第一页的内容
SubAgent
单一 Agent 模型的根本瓶颈:对于开放式的、路径不确定的复杂问题(比如技术研究、大规模重构),依赖单个智能体"一条路走到黑"的线性探索,效率低下且容易陷入局部最优。
多智能体系统的优势
- 一个主智能体(Orchestrator)可以将一个大问题分解为 \(n\) 个子问题,然后并行地启动 \(n\) 个 Subagent
- 每个 Subagent 都在自己独立的、干净的上下文窗口中,专注地研究自己的子问题。最后,它们只将高度浓缩的结论返回给主智能体
- 这相当于用 \(n \times ContextWindowSize\) 的总上下文容量,去解决一个远超单个智能体能力范围的问题
- 关注点分离:每个 Subagent 都可以拥有自己独特的 Prompt(性格)、工具集(技能)和探索轨迹。这避免了单一 Agent 的"精神分裂",让每个"专家"都能在自己的领域内做到最好
例子
任务:"请重构 xxx 模块,提升其性能,并确保整个过程符合我们公司的安全规范。"
- 性能优化:这需要 AI 扮演一个"性能专家"的角色。它的思维模式应该是激进的、探索性的,可能会尝试使用 unsafe 包、底层并发原语,或者引入新的高性能缓存库
- 安全审查:这需要 AI 扮演一个"安全审计员"的角色。它的思维模式应该是保守的、审慎的,会质疑每一个外部输入,并告诉你 unsafe 包很危险
Headless 模式:将 AI 能力集成到脚本与 CI
参考:极客时间 - 编程接口:驾驭Headless模式,将AI能力集成到脚本与CI
Headless 模式是指在无交互界面的情况下,将 AI Agent 的能力集成到自动化流程中。这对于将 AI 能力无缝融入现有的开发工作流至关重要。
核心概念:
- 无界面运行:AI Agent 可以在没有图形界面的环境中运行,通过命令行接口进行操作
- 自动化集成:可以将 AI 能力集成到 CI/CD 流程、脚本和自动化工具中
- 结构化输出:通过
stdin/stdout和结构化 JSON 输出,实现与外部系统的无缝对接
在 CI/CD 中的应用:
在 GitHub Actions 等 CI/CD 系统中集成 Claude Code 的典型流程包括:
- 获取上下文:从代码仓库、PR 信息等获取必要的上下文信息
- 调用 AI:通过 Headless 模式调用 AI Agent 处理任务
- 处理结果:解析 AI 返回的结构化结果
- 反馈闭环:将结果反馈到 CI/CD 流程中,完成自动化操作
关键技术点:
- stdin/stdout 通信:通过标准输入输出与 AI Agent 进行交互
- 结构化 JSON 输出:确保 AI 返回的结果可以被程序化处理
- 上下文管理:在自动化环境中有效管理和传递上下文信息
- 错误处理:建立完善的错误处理和重试机制
这种模式使得 AI 能力可以像传统工具一样,被集成到各种自动化流程中,真正实现 AI 原生开发工作流的自动化。
AI Agent 应用构建的新范式 - Don't Build Agents, Build Skills Instead
- Models 是 CPU 处理器
- Agent 运行时是操作系统(claude code, ai hub, openaisdk)
- Skills 是应用,是团队的数字资产,可以通过版本管理,不停地迭代和维护
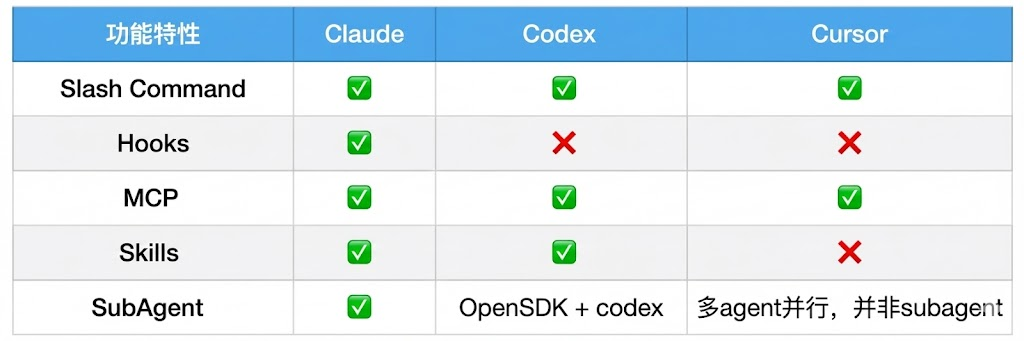
工具支持
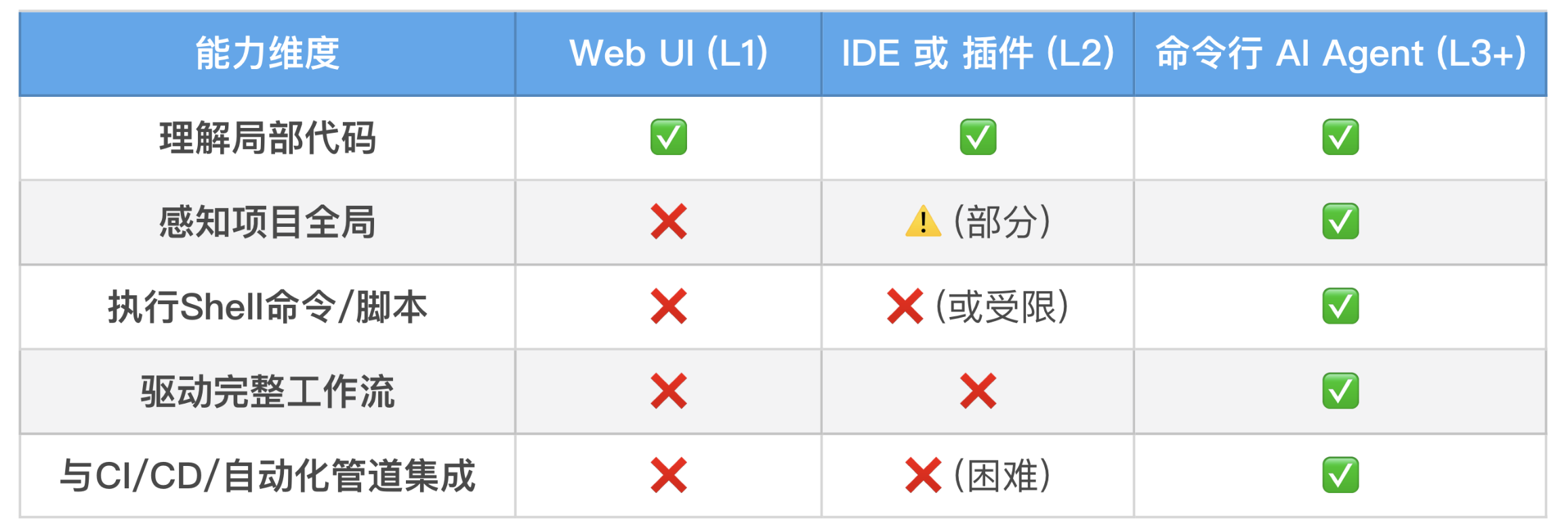
IDE VS CLI
- 权限越大,越危险 - 最小原则,最大危害
扩展功能支持对比
- 性价比推荐:claude cc + k2/glm4.6
实践
演示
自定义的桌面开发辅助工具 ZAssist
- Vibe Coding:cursor 结合代码分析 webview 相关的 logs
- Slash Command:
D:\ExceptionAnalysis\logs\browser-crash
团队共享 AI 产出物可能存在的问题
ZAssist 工具需求比较确定,如果有问题,可以修复;日志分析,如何保证在迭代的过程中行为符合预期?
- vibe coding 产品的 bug 如何修复?AI
- Spec-Driven Development:结构化的日志
- Skills 版本管理,有变更,就需要有对应的测试集
- 个人每个人都有一个分支去建立自己的 skill,然后让项目的 skill 从所有个人的分支中去不断的学习总结
参考
- https://code.claude.com/docs/
- 极客时间:AI原生开发工作流实战